From Pixels to Words: Exploring the Capabilities of Image-to-Text AI Tools
18th October 2023 • 15 min read — by Aleksandar Trpkovski

I had an idea to create an image-to-text automation tool for writing descriptions for my images. As a hobby landscape photographer, I have a lot of images, and this tool would speed up my workflow when posting on Instagram. I thought, "Well, I am a software developer. I can develop something like that very quickly, right?" I only need to add my credit card details to OpenAI, and then I can start using their API. This sounds simple enough. Well, let's discuss how it all went.
Imagine attaching an image and then starting a conversation with an AI assistant about the description you need help writing for that image. It would look something like this.
- First, we attach an image and ask the AI assistant for help.
- We request assistance in writing a description for the image, and the assistant provides one.
- Next, we ask the assistant to convert the description into an Instagram caption. We can see it adds emojis and hashtags as well.
- Then we also request an alternative text for the image to use on our website.
- Finally, we thank the assistant for their help.
What I just showed you is a screenshot of the app I developed, which includes a conversation with one of my images attached. The image was taken in 2016, and it shows the city of Melbourne. At the end of this document, I will provide you with the GitHub repo and a link to play with the app. But first, let's walk through the steps on how I achieved all of this.
Here is a diagram that visually represents the web app described above.
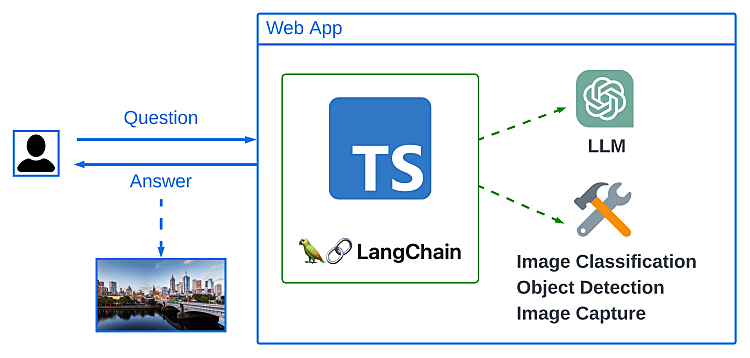
The diagram above provides a high-level overview of the app's functionality. The user submits a question about an attached image, and the web application responds with an answer. To achieve this, our app utilises LangChain, a powerful framework for working with Large Language Models (LLMs). LangChain supports both TypeScript and Python programming languages, and in our case, we are using TypeScript. We will become more familiar with LangChain and why we have chosen to work with it in the upcoming sections.
In addition, our app also uses additional tools to help us analyse the content of the image, giving us possible labels of classes or objects that might be included in the image.
Image Recognition Models for Text Generation and Object Detection
First, we will discuss the additional tools used to help us identify the content of the image. The LLM does not have any knowledge about the content of the image, so to write an effective description, we need to provide relevant information. We used two libraries to accomplish that: TensorFlow and Transformers.js from Hugging Face.
TensorFlow
Our app utilises two pre-trained models from TensorFlow. These models help to classify the image into meaningful labels with probability percentage and assist in detecting objects in photos.
Transformers.js
We also use two more models from Transformers.js, one to help us convert an image into meaningful words, and another for zero-shot image classification. We will explain what zero-shot image classification means later in this section.
We decided to use multiple models because each model predicts different parts of the image differently. Then all the labels will be passed through the zero-shot image classification model that will help us determine which labels are highly likely to be included in the image.
To demonstrate the models, we will use the same image as in our first chat, a photograph of the city of Melbourne that I took in 2016.
Image Classification with TensorFlow
Once the image has been uploaded the first model we are passing through is the Image Classification model from TensorFlow. This TensorFlow.js model does not require knowledge of machine learning. It can take any browser-based image elements (<img>, <video>, <canvas>, for example) as input and return an array of the most likely predictions and their confidences.
The array of classes and probabilities for our image can be seen below:
[
{
className: "castle",
probability: 0.21438449621200562,
},
{
className: "suspension bridge",
probability: 0.1847757250070572,
},
{
className: "lakeside, lakeshore",
probability: 0.18075722455978394,
},
];
Let's analyse the results above. The highest probability was for a castle, which is inaccurate since there is no castle in the image. The second highest probability was for a suspension bridge, which is correct since there is a bridge in the photo. The final prediction was for a lakeside or lake shore, which is also incorrect because there is a river in the image, not a lake.
Therefore, the only useful label from the predictions above is suspension bridge.
Object Detection with TensorFlow
We pass the image through the Object Detection model from TensorFlow as a second step. This model aims to identify multiple objects in a single image and is capable of detecting 80 different classes of objects. Unfortunately, in the case of the image of the city of Melbourne, the model was not able to detect any objects, resulting in an empty array. For demonstration purposes, the following example shows how the output would appear if we used an image in which objects could be detected:
[
{
bbox: [x, y, width, height],
class: "person",
score: 0.8380282521247864,
},
{
bbox: [x, y, width, height],
class: "kite",
score: 0.74644153267145157,
},
];
As we can see from the example above, this mode returns an array of bounding boxes with class names and confidence levels. Unfortunately, in our case, we received an empty array, so we did not get any predictions for our particular image.
Let's move on to the next models from Transformers.js.
Image captioning with Transformers.js
Image captioning is the process of generating a description or caption from an input image. This requires both natural language processing and computer vision to generate the caption. To accomplish this, we use a model called vit-gpt2-image-captioning from Transformers.js. Using this model, giving us the following output for the image above:
[
{
generated_text: "a bridge over a river with a city",
},
];
As we can see from the text above, the capture is pretty accurate. We got fairly accurate results for this particular image, but for every image, the results are different. When experimenting with different images, I sometimes get results that are not as accurate as this one. However, the next step will be to extract the nouns and verbs from the sentence above. How can we do that?
I won't go into the details of this step, but we will be using Chat GPT to ask it to return an array of all the nouns and verbs from the generated text above. It works quite well. Here are the results returned by Chat GPT:
["bridge", "river", "city"];
Basically, we can use only these three labels from the last model prediction and skip all the TensorFlow model usage. However, as I mentioned earlier, this is not the case for every image. In some cases, the Image Classification mode from TensorFlow can give us more accurate results. Therefore, we will keep both models for better predictions.
Now that we have all the predictions in place, the next step is to figure out which predicted labels are really included in the image. As human beings, we can easily determine that, but in the case of automation, we need to find a way to handle this automatically without human input. This is where the zero-shot image classification model that I mentioned earlier comes into play.
Zero-shot image classification with Transformers.js
Zero Shot Classification is the task of predicting a class that wasn't seen by the model during training. In other words, a zero-shot model allows us to classify data that wasn't used to build the model. For example, imagine a child is asked to recognise a zebra in a zoo. The child has never seen a zebra before, but they have seen a horse. By telling the child that a zebra is very similar to a horse but with black and white stripes, the child can recognise a zebra easily. This is essentially how the model works.
This is the opposite of what we've done before. In previous models, we give them an image, and they give us predictions on what can be included in the image. In zero-shot image classification, we provide both text predictions and an image, and the model can tell us which texts are highly likely to be included in the image.
In our case, we will be using clip-vit-base-patch32 from Transformers.js, which utilises the CLIP model developed by researchers at OpenAI.
All predicted labels previously assigned to the image are passed to this model. As a result, we receive the following output:
[
{
score: 0.36474844813346863,
label: "bridge",
},
{
score: 0.22917157411575317,
label: "suspension bridge",
},
{
score: 0.223050057888031,
label: "city",
},
{
score: 0.1010189950466156,
label: "river",
},
{
score: 0.0377478264272213,
label: " lakeshore",
},
{
score: 0.02330002561211586,
label: "lakeside",
},
{
score: 0.020963076502084732,
label: "castle",
},
];
As seen from the results above, this model is capable of giving pretty accurate scores for all the labels and determining which are most likely to be included in the image. Based on my previous experimentation while developing this application, I realised that the top three to five labels are fairly accurate. For our app, we will only focus on the top four labels. Next, we will explore the capabilities of LangChain and the specific feature we used from this framework to generate a meaningful description.
LangChain
Working with LLMs can be challenging, especially when working on a complex web application. I find managing memory and writing clear instructions (prompts) to be the two most challenging aspects. Fortunately, LangChain provides a solution to both of these issues and more.
LangChain is an open-source framework that supports both Python and TypeScript. It allows you to build applications that use LLMs. LangChain provides a simple interface that makes it easy to connect LLMs to our application. One of the key features that LangChain provides to help manage different prompts is chains. LangChain has different types of chains, and the one we use in our application is called the Multi-Prompt Chain. This allows us to use more than one prompt template and pick an appropriate prompt based on the user's question.
To make this clearer, let me give an example of how this applies to our application. We use different prompt templates in our application for different purposes. For example, we use one prompt to give instructions to the model on how to write a description, another prompt to handle Instagram descriptions, and a third prompt for writing an alt text. Each of these prompt templates has different instructions. For instance, when we want the model to assist the user in writing an Instagram caption, we provide instructions to add some emojis and hashtags. So, when someone asks for writing a description or an alt text, different instructions are given. We can fine-tune the output based on specific prompt templates for specific scenarios. In my experience, writing multiple short prompts instead of one large single prompt drastically improves the quality of the model's output.
Memory is another concept that LangChain solves out of the box. For applications like chatbots, it is essential that they can remember previous conversations. However, by default, LLMs do not have any long-term memory unless you input the chat history. LangChain solves this problem by providing several options for dealing with chat history: keeping all conversations, keeping only the latest number of conversations, or summarising the conversation. In our app, we use the option to keep the latest number conversations, so we remember the last ten conversations.
These are only a small number of the features that LangChain can offer. I highly recommend checking the LangChain documentation to learn more about the awesome features this tool provides.
Conclusion
I enjoyed developing this chatbot that helps humans write their descriptions base on an image. This is a beta version, and I have plans to improve it in the future, but it's a good starting point. It's still not perfect and can sometimes get confused, but as technology progresses and new models become available, I'm confident we'll be able to get much better results.
If you want to try it, follow this link: https://image-to-text-ai-chat.vercel.app/. All you need to do is provide your OpenAI API key at the bottom of the page.
For those who want to see the source code, it's available on GitHub at this link: https://github.com/Suv4o/Image-to-Text-AI-Chat. Please keep in mind that this only works on Chrome and Mozilla for now. Safari is not currently supported. I hope you enjoy it!